前回に引き続き、今回はNotion APIで取得したページのデータから記事のMarkdownファイルを生成するまでに苦労した点を書いていきたい。
ページプロパティの読み取り
前回は Notion 公式のJavaScript向けクライアントライブラリ(以下 @notionhq/client) を使ってページやブロックのデータを取得した。
最終的に Hugo で記事としてビルド可能なMarkdownファイルを生成するためには、記事のタイトルやタグなどを保持する Frontmatter 情報と、記事の本文の情報の両方を Notion のページから読み取って変換しなければならない。
しかしこれも思いどおりにはいかず、いくつかの工夫が必要だった。
ページプロパティオブジェクトのキーがIDじゃない
前回の記事で PageObject 型が properties フィールドを持つように型を定義したが、このフィールドで提供されるページプロパティ情報がなかなか扱いづらいデータモデルだった。
Notion のページプロパティはページに紐付けられるメタ情報のセットで、次の画像のようなプロパティ名と値のKey-Valueマップのデータである。
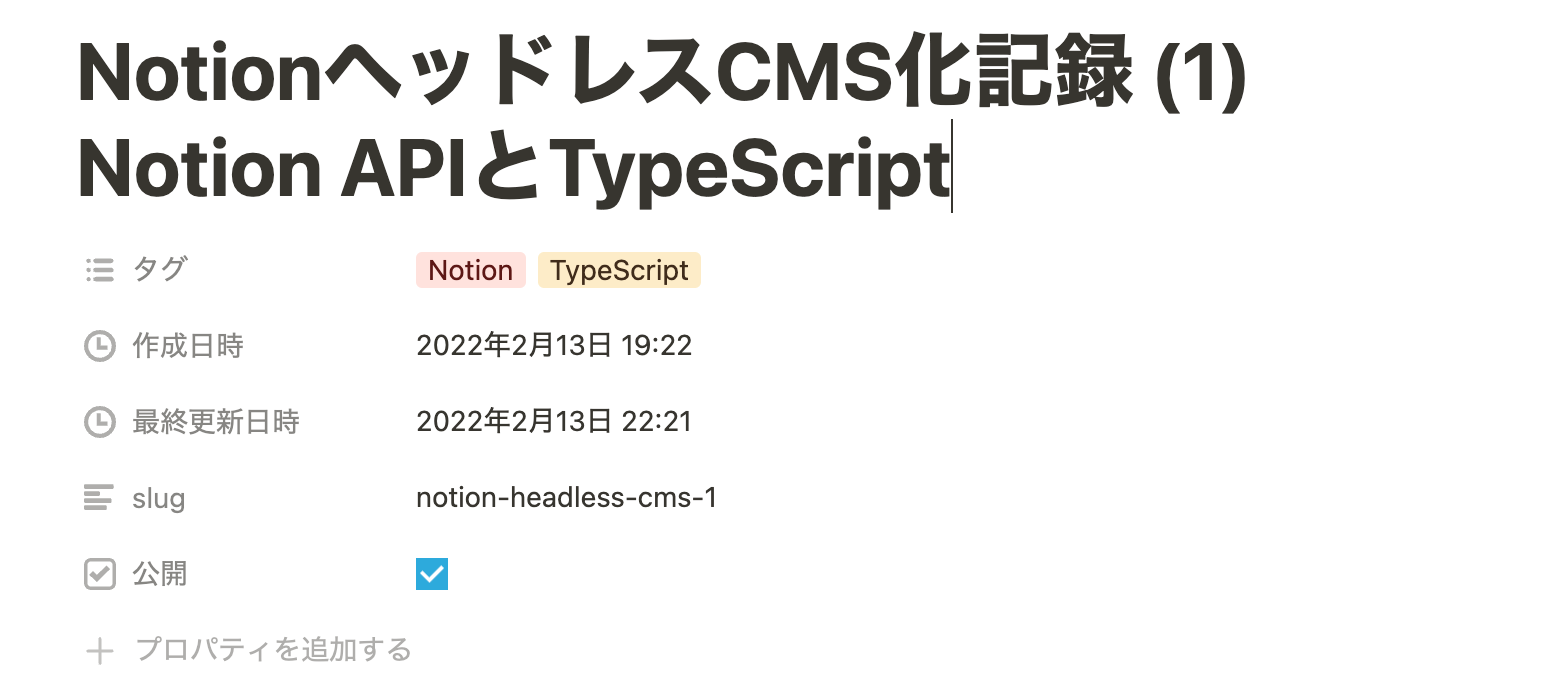
問題はこのプロパティ情報を格納した PageObject の properties オブジェクトが、自由記述のプロパティ表示名をキーとして、プロパティ固有のIDが値側に格納されていることである。
properties: Record<string, {
type: "title";
title: Array<RichTextItemResponse>;
id: string;
} | {
type: "rich_text";
rich_text: Array<RichTextItemResponse>;
id: string;
} | ...
}>;Notion の GUI 上ではいつでもプロパティ表示名を変更できるため、キー側をもとに特定のプロパティを探索するのは堅牢性に欠ける。まずはプロパティのIDをキーにしたマップオブジェクトに詰め替えることから始めることになった。
const properties = Object.fromEntries(
Object.values(page.properties).map((prop) => [prop.id, prop])
);プロパティの型をプロパティタイプから推論する
Notion のページプロパティはいくつものデータ型をサポートしており、プロパティオブジェクトの type フィールドからその種別を特定できる。逆にいえば、プロパティIDで取得しただけではすべてのデータ型のUnion型になっているためそれぞれのデータ型固有のフィールドにアクセスできない。
そこで、プロパティのマップオブジェクトからデータ型を指定しつつ特定のプロパティを取り出すために、次のようなユーティリティ関数を作成した。IDとデータ型が一致すればそのプロパティを返し、一致しなければ null を返す。そして取り出したプロパティは Type Guard によりデータ型が確定する。
export function createPagePropertyMap(page: PageObject) {
const properties = Object.fromEntries(
Object.values(page.properties).map((prop) => [prop.id, prop])
);
return {
get<PropType extends string>(id: string, type: PropType) {
const prop = properties[id];
if (!prop || !matchPropertyType(prop, type)) {
return null;
}
return prop;
},
} as const;
}
function matchPropertyType<PropType extends string, Prop extends { type: string }>(
property: Prop,
type: PropType,
): property is MatchType<Prop, { type: PropType }> {
return property.type === type;
}このユーティリティを使ってページプロパティ情報からブログ記事のメタデータとなる Frontmatter 情報が作成できるようになった。
async renderPost(post: NotionPost, options: { forceUpdate?: boolean } = {}) {
const { created_time: remoteCreatedAt, last_edited_time: remoteUpdatedAt, archived } = post;
if (archived) {
return;
}
const props = createPagePropertyMap(post);
const title = props.get('title', 'title')?.title[0]?.plain_text;
const slug = props.get('Y~YJ', 'rich_text')?.rich_text[0]?.plain_text ?? null;
const tags = props.get('v%5EIo', 'multi_select')?.multi_select.map((node) => node.name) ?? [];
const publishable = props.get('vssQ', 'checkbox')?.checkbox ?? false;
if (title == null || slug == null) {
console.warn(`title or slug is null: ${JSON.stringify(post, null, 2)}`);
return;
}
const frontmatter = renderFrontmatter({
title,
date: remoteCreatedAt,
updated_at: remoteUpdatedAt,
tags,
draft: !publishable,
source: post.url,
});
// ...
}
export function renderFrontmatter(params: Record<string, unknown>): string {
const frontmatter = yaml.dump(params, { forceQuotes: true });
return [`---`, frontmatter, `---`].join('\n');
}Markdownファイルの生成
ページのブロックデータをもとにMarkdown文字列へ変換し、記事ファイルとして書き込むのはそれほど苦労しなかったが、注意するポイントはあった。
ファイルアップロードの画像ブロックはURLが失効する
Notion の画像ブロックは外部URLを指定するものと、Notionへ直接画像をアップロードして埋め込むものと2種類あるが、ファイルアップロードによる画像ブロックはURLが一定時間で失効する。そのため、ブログ記事として永続化させるためにはURLが生きているうちに画像をダウンロードし、レポジトリ内へ保存したうえで相対パスによって参照することになる。
const renderer: BlockObjectRendererMap = {
// ...
image: async (block) => {
switch (block.image.type) {
case 'external':
return `\n\n`;
case 'file':
// 画像をDLしてローカルファイルの相対パスを返す
const imagePath = await externalImageResolver(block.image.file.url);
return `\n\n`;
}
},
// ...
} as const;ネストしたリストは子ブロック扱い
前回の記事でも触れたが、箇条書きリスト、番号付きリストはネストさせると子ブロックを持つようになる。ネストの深さに応じてインデントされるように、前回保持させた depth フィールドを使う。
bulleted_list_item: (block) => {
const indent = '\t'.repeat(block.depth);
const text = renderRichTextArray(block.bulleted_list_item.text);
return `${indent}- ${text}\n`;
},
numbered_list_item: (block) => {
const indent = '\t'.repeat(block.depth);
const text = renderRichTextArray(block.numbered_list_item.text);
return `${indent}1. ${text}\n`;
},リッチテキストの変換
Notion のテキストはほとんどのブロックでリッチテキストとして表現され、文字装飾が可能だ。すべての装飾をMarkdownへ変換しても保持するのは大変なので、ブログ記事として必要なものに絞って変換した。 annotations のそれぞれのフラグは排他ではなくすべての組み合わせがありえるため、優先順をつけて再帰的に処理することとした。ブログ側ではインラインコードの装飾は除去し、Markdown側で2文字のマーカーが必要なものから順番に処理する。リンクや改行の処理は最後になるようにした。
type RichTextObject = {
plain_text: string;
href: string | null;
annotations: {
bold: boolean;
italic: boolean;
strikethrough: boolean;
underline: boolean;
code: boolean;
};
};
function renderRichTextArray(array: RichTextObject[]): string {
return array.map(renderRichText).join('');
}
function renderRichText(richText: RichTextObject): string {
const { plain_text, href, annotations } = richText;
if (annotations.code) {
return `\`${plain_text}\``;
}
if (annotations.bold) {
return renderRichText({
...richText,
plain_text: `**${plain_text}**`,
annotations: { ...annotations, bold: false },
});
}
if (annotations.italic) {
const mark = plain_text.startsWith('*') ? '_' : '*';
return renderRichText({
...richText,
plain_text: `${mark}${plain_text}${mark}`,
annotations: { ...annotations, italic: false },
});
}
if (annotations.strikethrough) {
return renderRichText({
...richText,
plain_text: `~~${plain_text}~~`,
annotations: { ...annotations, strikethrough: false },
});
}
if (annotations.underline) {
return renderRichText({
...richText,
plain_text: `__${plain_text}__`,
annotations: { ...annotations, underline: false },
});
}
if (href) {
return renderRichText({ ...richText, plain_text: `[${plain_text}](${href})`, href: null });
}
if (plain_text.includes('\n')) {
return plain_text.replace(/\n/g, ' \n');
}
return plain_text;
}まとめ・次回予告
こうして Notion APIから取得したページデータをもとにMarkdownファイルを生成することができた。
次回は、この記事生成を含むデプロイフローが Notion で記事を書いたあと自動的に実行されるようにするための、GitHub Actionsのワークフローについて書く。